Revisiting the SSH honeypot

Last year I ran a simple experiment to open up an SSH honeypot from my home lab and see where from and how many times it got “tickled”. Whilst it worked ok, I wasn’t really happy with the visualisation of the data, it was a bit poor, so I decided to revisit it again. Unfortunately I had blown away all the code so I had to start from scratch again. Luckily it’s fairly easy to do.
Firstly let’s just spin up a docker container to house our ssh honeypot. I’m using a docker image whereby there is no account, password or shell for the SSH to connect to and all it does is record the user IP, user ID and password for each attempt. There is no way anyone can actually log in. It’s a useful method to see the amount of subnet scanning going on and what sort of scripted attacks are commonplace.
Once we have our container up and running, our firewall redirecting external port 22 to our honeypot, we just need a method of extracting the logs and visualising them. We can pull the log file using docker exec:
docker exec ssh-honeypot cat /ssh-honeypot/ssh-honeypot.log | grep -v "Session" | grep -v "Error" | awk -F']' '{print $2}' | awk -F' ' '{print $1}' | grep -o "[0-9]\+\.[0-9]\+\.[0-9]\+\.[0-9]\+" > /home/jtate/ip_addresses.txt
What we are doing here is pulling the logs and filtering them to just output a list of all the IP addresses for each attempt. Due to the scripted nature of the attacks there will be a lot of duplicate IPs which we will account for in the next step.
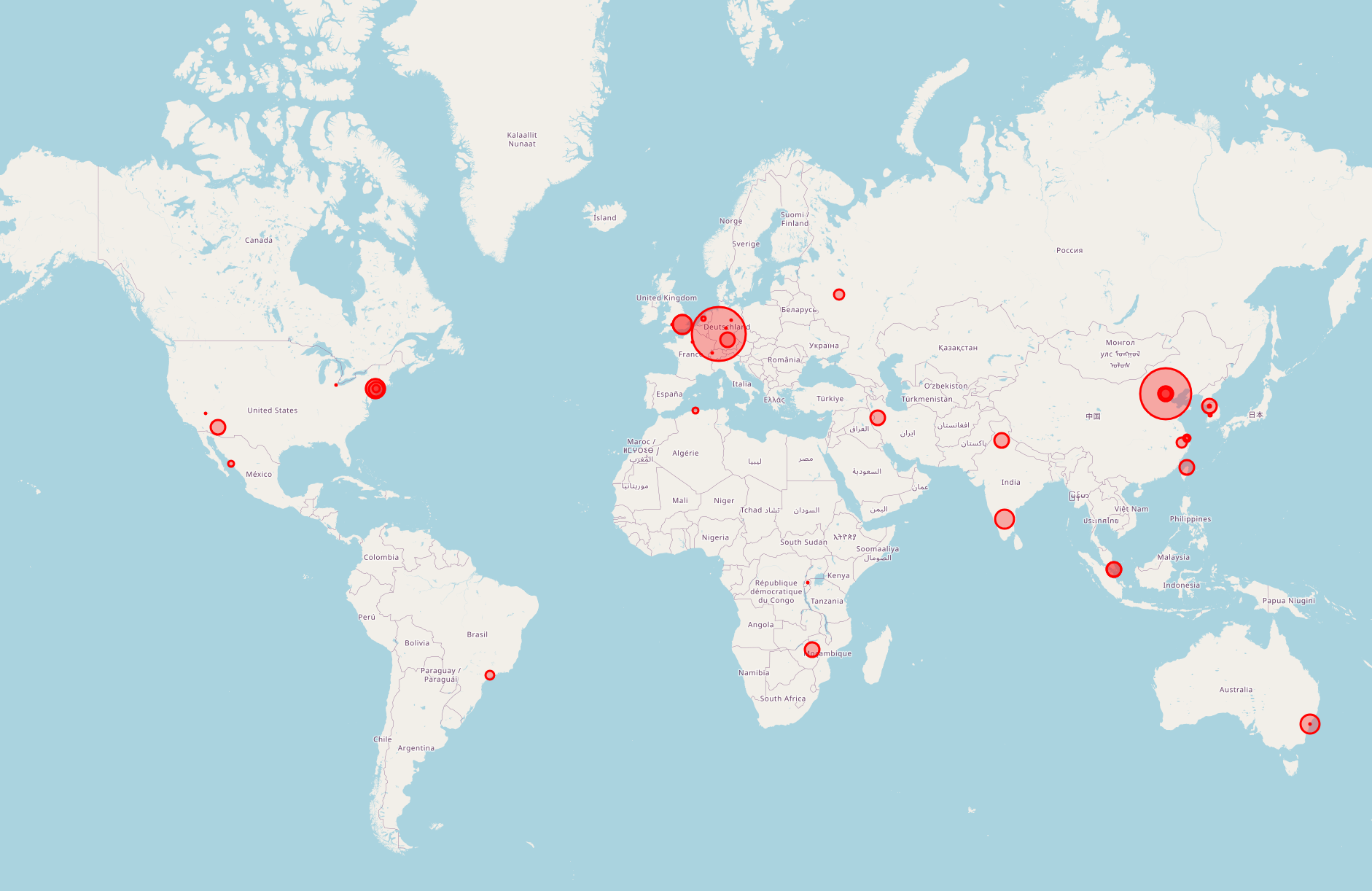
Next we want to visualise this data on a map, specifically highlighting the areas where the most attacks come from. I have written some python to do just that using the geopy library, with the geo matching being provided by ipinfo.io . A free account comes with 50K API calls per month, so as long as I count the entries per IP before I resolve the geo-location, I can keep that request amount to a minimum.
import requests
import folium
from geopy.geocoders import Nominatim
from collections import Counter # Import the Counter class
# Replace 'YOUR_API_KEY' with your actual ipinfo.io API key
IPINFO_API_KEY = '************'
def get_geolocation(ip):
url = f"http://ipinfo.io/{ip}/json?token={IPINFO_API_KEY}"
response = requests.get(url)
data = response.json()
if 'loc' in data:
lat, lon = data['loc'].split(',')
return float(lat), float(lon)
return None
def main():
input_filename = "ip_addresses.txt"
with open(input_filename, "r") as file:
ip_list = [line.strip() for line in file.readlines()]
# Count occurrences of each IP address
ip_counter = Counter(ip_list)
# Initialize the map
m = folium.Map(location=[0, 0], zoom_start=3)
for ip, count in ip_counter.items():
location = get_geolocation(ip)
if location:
marker_size = count / 4 # Marker size based on the count of similar IP entries
label = f"Attackers: {count}"
folium.CircleMarker(
location=location,
radius=marker_size,
color='red',
fill=True,
fill_color='red',
fill_opacity=0.3,
popup=ip,
tooltip=label,
).add_to(m)
output_filename = "/var/www/html/ip_heatmap.html"
m.save(output_filename)
print(f"Heatmap saved as '{output_filename}'")
if __name__ == "__main__":
main()
As you can see the script pulls in the ip addresses from a txt file (output from the docker exec, which is run every 5mins by cron job). It matches the duplicate IP’s and also counts the number of instances of each duplicate. This then all gets passed to follium map whcih visualises the data based upon the geolocation and places markers on the map whose size corresponds to the count value. The map is updated every 12 hours to keep the API calls below the monthly limit. The current map can be seen here:
