Kasten Backup & Restore of the Strimzi Kafka Operator


Kafka Data Protection & The Problem
Kafka is a very popular platform for data flow and pipelining within the enterprise space, especially in Kubernetes environments, where data needs to be shared often between namespaces, pods, applications and clusters. It does pose challenges when assessing it's data protection needs.
Whilst most of the data is transient, being governed by a timeout removal schedule, the issue is there is no formal backup procedure for Kafka. In fact even Confluence, Kafka's vendor, does not provide a tool for native backup. This doesn't mean it's not important to protect the data. The 'normal' procedure would be to protect the data upstream and downstream from the messaging queue, usually in other applications, but not the data in transmission. However there maybe scenarios where recovery of this transient data is required, and as long as recovery is done before the data expiry time window closes, that data can be recovered.
From a Kasten perspective it's just another classical Kubernetes application, however the Kafka architecture does require some finesse in restoration. Firstly it's important to understand what Kafka is and the components.
This post will outline the process of using Kasten to achieve this restoration of Kafka data.
Strimzi
Strimzi is a popular operator in the Kubernetes space, that streamlines and simplifies the deployment of Kafka clusters. It's fairly simple in it's operating model and provides a useful management of Kafka clusters at scale:
- The operator is installed via HELM in it's own namespace and is configured to watch ALL namespaces for Kafka configurations (via a CRD).
- When the operator finds a namespace with a Kafka configuration, it will deploy that configuration into the end namespace and manage the spinning up all resources.
As such it's actually very easy to build and deploy multiple Kafka clusters in a very quick fashion. In the below example we will deploy a simple Strimzi Kafka cluster, populate some sample data and backup/restore it.
Deploying Strimzi & Creating a Kafka Cluster
Assuming we have a working cluster with a default storageclass, HELM installed and kubectrl access to the cluster we can go ahead and install the Strimzi operator:
helm upgrade --install --create-namespace -n strimzi-operator strimzi-cluster-operator oci://quay.io/strimzi-helm/strimzi-kafka-operator --set watchAnyNamespace=true
Note the option to watch ANY namespace. This can also be specifically set to watch a list of prescribed namespaces.
Next we want to define the Kafka cluster variables:
apiVersion: kafka.strimzi.io/v1beta2
kind: Kafka
metadata:
name: my-cluster
spec:
kafka:
version: 3.7.0
replicas: 3
listeners:
- name: plain
port: 9092
type: internal
tls: false
- name: tls
port: 9093
type: internal
tls: true
config:
offsets.topic.replication.factor: 3
transaction.state.log.replication.factor: 3
transaction.state.log.min.isr: 2
default.replication.factor: 3
min.insync.replicas: 2
inter.broker.protocol.version: "3.7"
storage:
type: jbod
volumes:
- id: 0
type: persistent-claim
size: 100Gi
deleteClaim: false
zookeeper:
replicas: 3
storage:
type: persistent-claim
size: 100Gi
deleteClaim: false
entityOperator:
topicOperator: {}
userOperator: {}
We can define the number of replicas and the size of the PVC volumes depending upon our requirements, we can then create the Kafka application namespace and deploy the Kafka config. The Strimzi operator will pick this up and start the deployment automatically, creating all application objects required.
kubectl create ns kafka-1
kubectl create -f kafka.yaml -n kafka-1
After a few minutes, check the state of your cluster:
kubectl get kafka -n kafka-1
You should get something like this:
NAME DESIRED KAFKA REPLICAS DESIRED ZK REPLICAS READY METADATA STATE WARNINGS
my-cluster 3 3 True ZooKeeper
You should also see a number of pods spun up within the Kafka-1 namespace:

Creating a Kafka Topic and Data
Next we can create an example Kafka topic, deploy a client pod and push some sample data into the cluster.
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaTopic
metadata:
name: my-topic
labels:
strimzi.io/cluster: my-cluster
spec:
partitions: 1
replicas: 1
config:
retention.ms: 14400000
segment.bytes: 1073741824
Here we can set the replicas, partition count and the retention period. Then apply this to the cluster and check it's deployed:
kubectl apply -f topic.yaml -n kafka-1
kubectl get kafkatopic -n kafka-1

Lastly lets spin up a client pod within the kafka-1 namespace, console to it and inject some data into our topic:
kubectl run -n kafka-1 client --image quay.io/strimzi/kafka:latest-kafka-3.7.0 --command -- tail -f /dev/null
kubectl exec -n kafka-1 -it client -- bash
This will drop us into the console of the pod from where we can inject the data:
./bin/kafka-console-producer.sh --broker-list my-cluster-kafka-bootstrap:9092 --topic my-topic
>1
>2
>test
>5
>6
>^C
exit
Once you exit the pod, you can read the topic contents directly from kubectl:
kubectl exec -n kafka-1 -it client -- bash
./bin/kafka-console-consumer.sh --bootstrap-server my-cluster-kafka-bootstrap:9092 --topic my-topic --offset 0 --partition 0
You should get an output like this:
1
2
test
5
6
^CProcessed a total of 5 messages
Backup & Restore with Kasten
Now that we have a working cluster we can protect it with Kasten. I'm going to assume you already have a working Kasten config, with export location and any required integrations. If not that is covered in other blog posts and the Kasten docs site.
Backup of Kafka is done using the normal snapshot methodology, so a straight forward snapshot and export to an external location. Nothing special is required. Once you have the backup restore point available we can move onto the restore. There is one thing that is important to note about the restore, it must be back to the original location as the operator makes reference to it in the Kafka definition, you cannot just clone it alongside it's original namespace to test the restore...this won't work (and you will get error messages about lack of access to secrets etc). What must be done is delete the entire namespace before attempting a restore. Of course in a DR situation, this is a moot point. We must only do this as we are testing the restore on the same Kubernetes cluster as the original install.
Before we delete the namespace it's good practice to delete the topic first, otherwise it can be left as a hanging resource:
kubectl delete kafkatopic -n kafka-1 --all
Then proceed to delete the Kafka namespace:
kubectl delete ns kafka-1
Now we can get to the restore, log into Kasten and find the list of Applications and filter for "Removed":
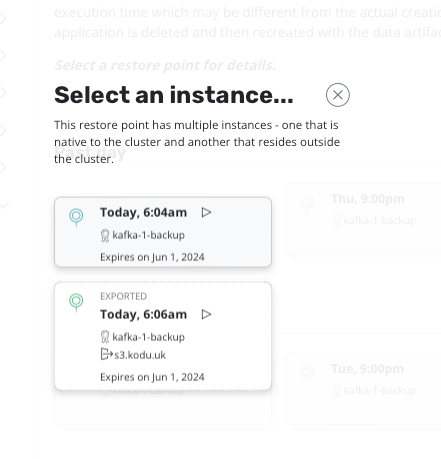
Select the kafka-1 application and choose the latest restore point from your external location:
Lastly we need to selectively choose the items we restore. We cannot restore all the pods, deployments etc, as these are dynamically created by the Strimzi operator. To do so causes the zookeepers and brokers to fail to come up as the operator clashes with the recovered objects. What we need to recover is just the select items required for the operator to do it's job. Make sure all PVC's are selected and ONLY the below items (namely the configmaps, kafkas, kafkatopics and secrets...also any kafkausers if you have them):
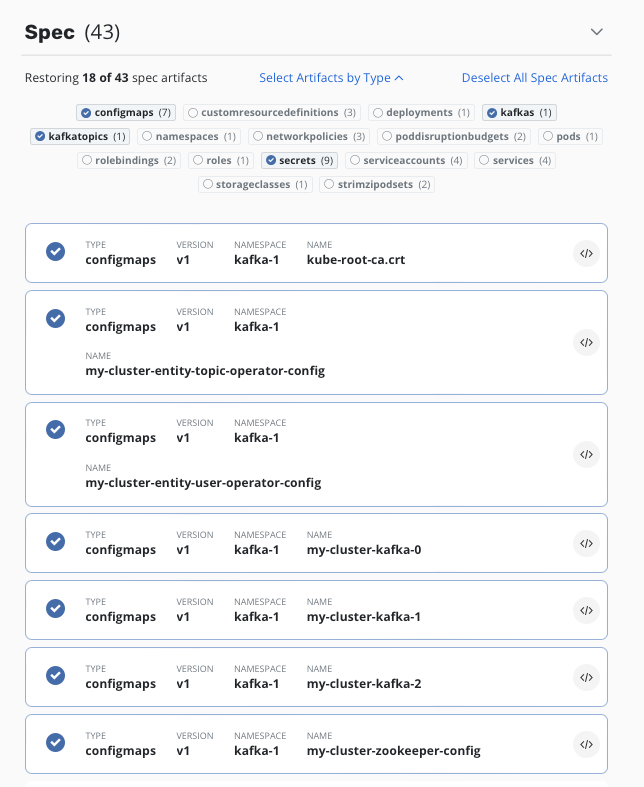
Once the restore is completed, the Strimzi operator will again see the Kafka configuration and start the deployment process, this time binding to the restored PVC's instead of creating new ones. We will yet again see the spin up of all the pods:

Using the method above already described you can deploy the client pod and dump the contents of the topic and confirm the data is restored. Of course you can also include the client pod as part of the restore process which will remove the need for you to deploy it again.
Conclusion
Kafka is central to most business queuing needs and dependant upon the timeout setting, restoring it might be of critical importance to other applications. I hope this highlights that it's not that complicated of a prospect with Kasten and the use of an intelligent operator model.